
第一讲 深度学习简介
编辑一、什么是深度学习
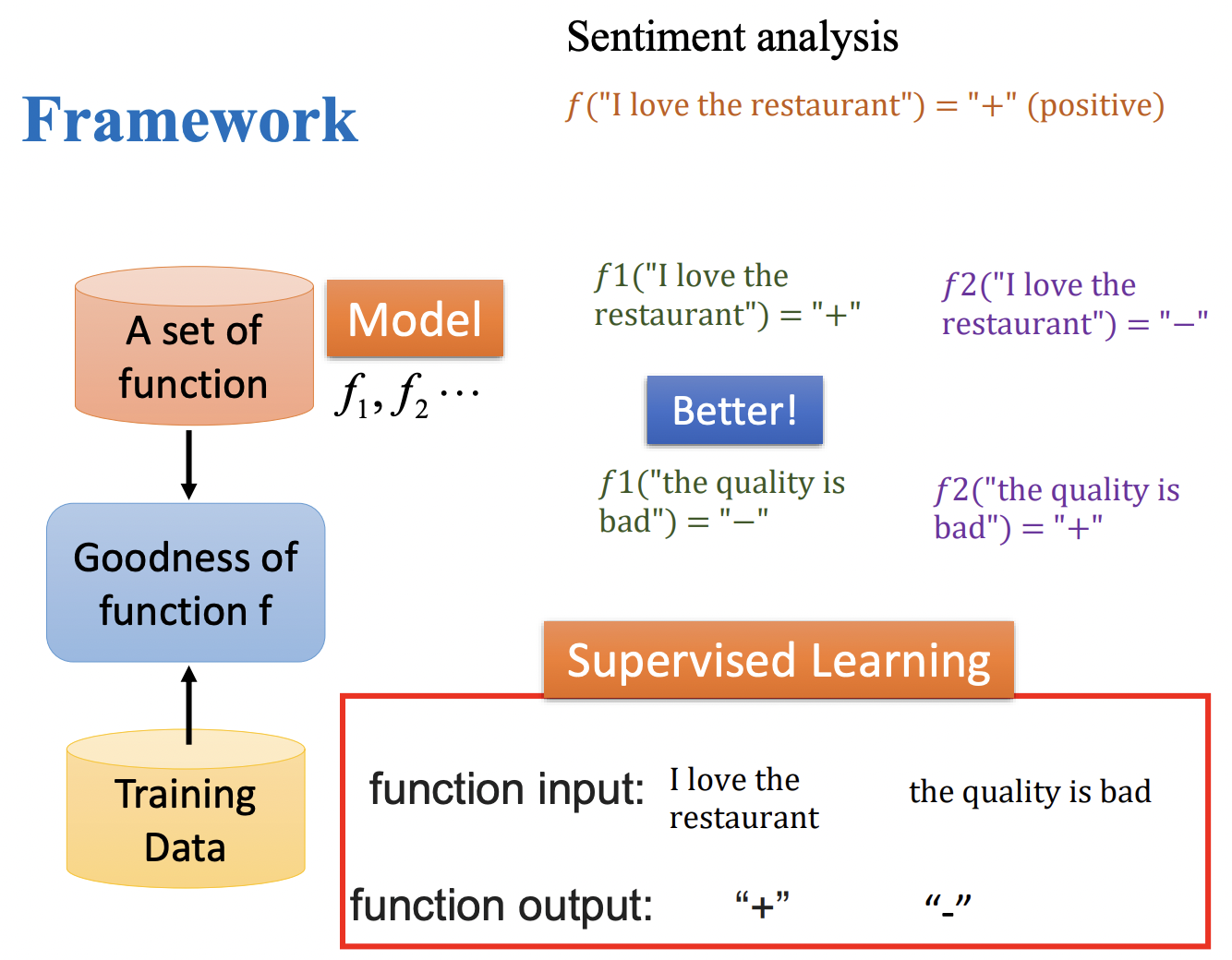
机器学习(Machine Learning)
-
机器学习的过程就是一个寻找最佳函数的过程。
-
机器学习运作的架构:
- 构建一个函数集合。
- 将训练数据放入函数集合计算,得到函数计算的结果。
- 通过比较结果,得到最佳的函数(模型)。
深度学习(Deep Learning)
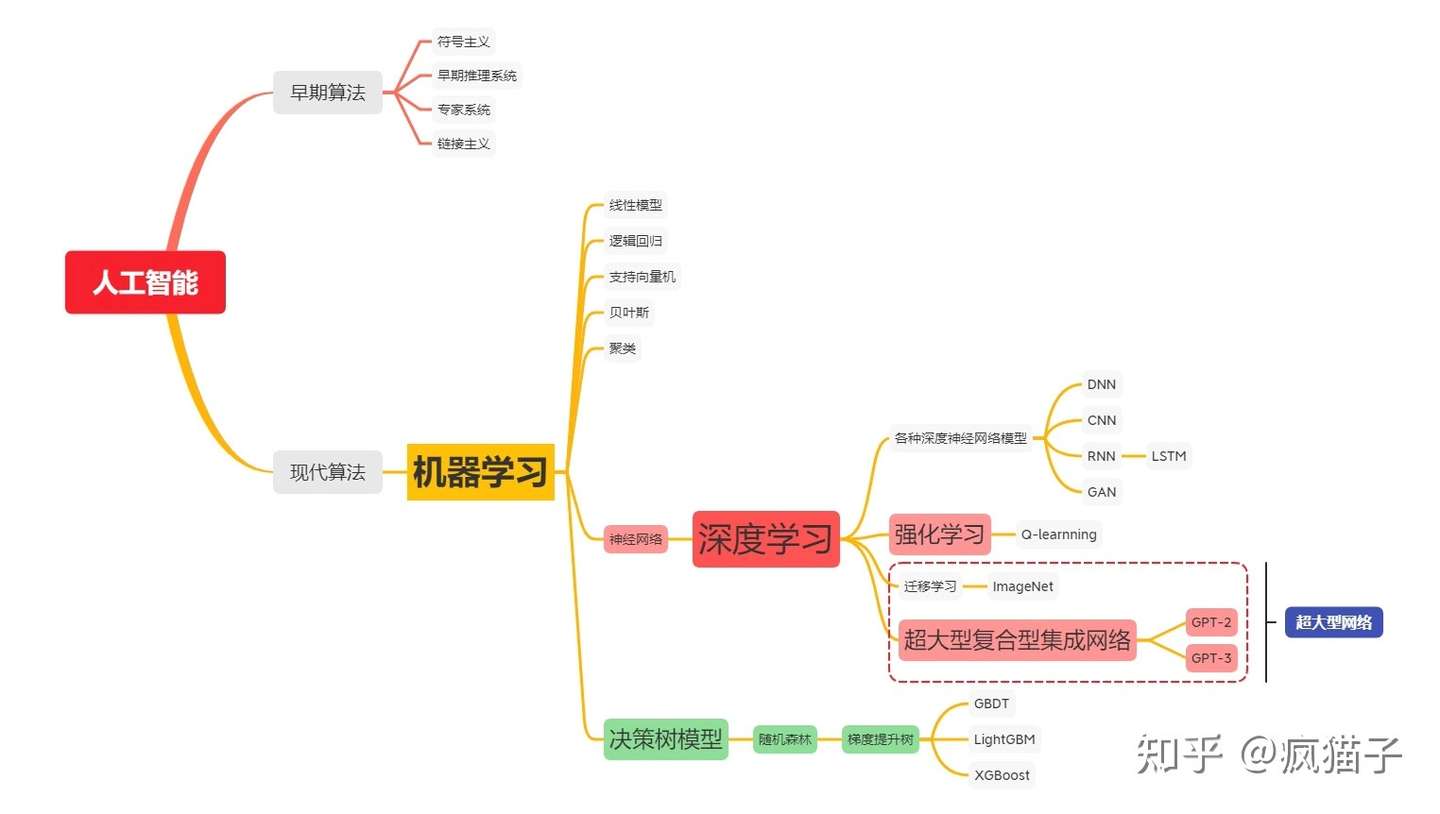
- 深度学习是机器学习的其中一个分支,和机器学习的神经网络一块高度相关。
机器学习和深度学习的区别
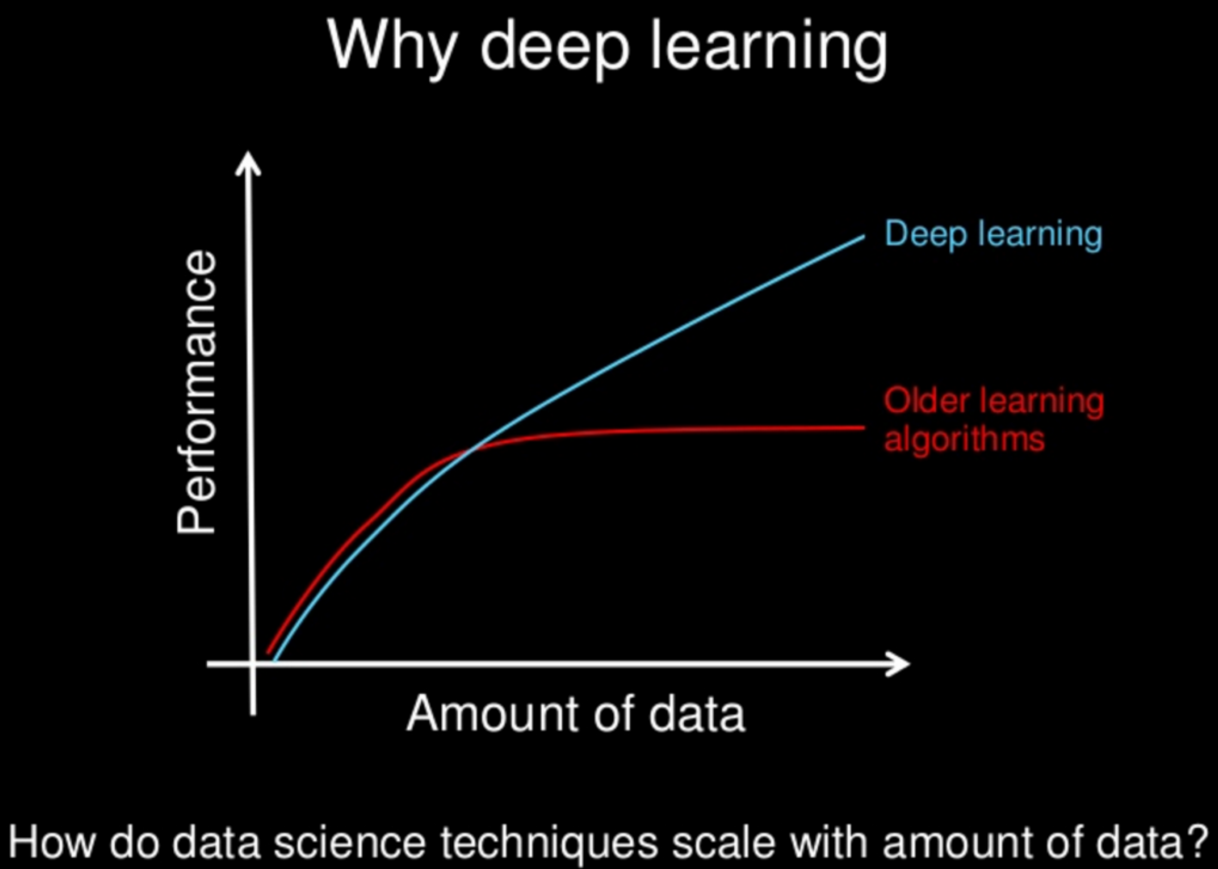
数据依赖性
深度学习与传统的机器学习最主要的区别在于随着数据规模的增加其性能也不断增长。当数据很少时,深度学习算法的性能并不好。这是因为深度学习算法需要大量的数据来完美地理解它。另一方面,在这种情况下,传统的机器学习算法使用制定的规则,性能会比较好。下图总结了这一事实。
硬件依赖
深度学习算法需要进行大量的矩阵运算,GPU 主要用来高效优化矩阵运算,所以 GPU 是深度学习正常工作的必须硬件。与传统机器学习算法相比,深度学习更依赖安装 GPU 的高端机器。
特征处理
特征处理是将领域知识放入特征提取器里面来减少数据的复杂度并生成使学习算法工作的更好的模式的过程。特征处理过程很耗时而且需要专业知识。深度学习尝试从数据中直接获取高等级的特征,这是深度学习与传统机器学习算法的主要的不同。基于此,深度学习削减了对每一个问题设计特征提取器的工作。
问题解决方式
在传统的机器学习中,传统机器学习通常会将问题分解为多个子问题并逐个子问题解决最后结合所有子问题的结果获得最终结果。相反,深度学习提倡直接的端到端的解决问题。例如:在做物体识别的时候,传统机器学习会讲任务分为物体检测和物体识别两步,但是深度学习直接一步到位。
执行时间
通常情况下,训练一个深度学习算法需要很长的时间。这是因为深度学习算法中参数很多,因此训练算法需要消耗更长的时间。而机器学习的训练会消耗的时间相对较少,只需要几秒钟到几小时的时间。但两者测试的时间上是完全相反。深度学习算法在测试时只需要很少的时间去运行。
可解释性
假设我们适用深度学习去自动为文章评分。深度学习可以达到接近人的标准,这是相当惊人的性能表现。但是这仍然有个问题。深度学习算法不会告诉你为什么它会给出这个分数。而传统的机器学习算法中的决策树算法就能够很清晰地说明哪一步影响了最终的判分。深度学习更像是一个炼丹的炉子,你把数据和函数设置好以后就开始训练,但是你并不知道里面究竟发生了什么反应,你只能得到一个最终的结果。
二、深度学习历史
深度学习算法发展大致分为五个时期。
第一阶段:模型提出
-
在1943年,心理学家Warren McCulloch和数学家WalterPitts和最早描述了一种理想化的人工神经网络,并构建了一种基于简单逻辑运算的计算机制。他们提出的神经网络模型称为MP模型。
-
阿兰·图灵在1948年的论文中描述了一种“B型图灵机”。(赫布型学习)
-
1951年,McCulloch和Pitts的学生Marvin Minsky建造了第一台神经网络机,称为SNARC。
-
Rosenblatt [1958]最早提出可以模拟人类感知能力的神经网络模型,并称之为感知器(Perceptron),并提出了一种接近于人类学习过程(迭代、试错)的学习算法。
第二阶段:冰河期
-
1969年,Marvin Minsky出版《感知器》一书,书中论断直接将神经网络打入冷宫,导致神经网络十多年的“冰河期”。他们发现了神经网络的两个关键问题:(1)基本感知器无法处理异或回路。(2)电脑没有足够的能力来处理大型神经网络所需要的很长的计算时间。
-
1974年,哈佛大学的Paul Webos发明反向传播算法,但当时未受到应有的重视。
-
1980年,Kunihiko Fukushima(福岛邦彦)提出了一种带卷积和子采样操作的多层神经网络:新知机(Neocognitron)。
第三阶段:反向传播算法引起的复兴
-
1983年,物理学家John Hopfield对神经网络引入能量函数的概念,并提出了用于联想记忆和优化计算的网络(称为Hopfield网络),在旅行商问题上获得当时最好结果,引起轰动。
-
1984年,Geoffrey Hinton提出一种随机化版本的Hopfield网络,即玻尔兹曼机。
-
1986年, David Rumelhart和James McClelland对于联结主义在计算机模拟神经活动中的应用提供了全面的论述,并重新发明了反向传播算法。
-
1986年,Geoffrey Hinton等人将引入反向传播算法到多层感知器。
-
1989 年,LeCun等人将反向传播算法引入了卷积神经网络,并在手写体数字识别上取得了很大的成功。
第四阶段:流行度降低
-
在20世纪90年代中期,统计学习理论和以支持向量机为代表的机器学习模型开始兴起。
-
相比之下,神经网络的理论基础不清晰、优化困难、可解释性差等缺点更加凸显,神经网络的研究又一次陷入低潮。
第五阶段:深度学习的崛起
-
2006年,Hinton等人发现多层前馈神经网络可以先通过逐层预训练,再用反向传播算法进行精调的方式进行有效学习。
-
深度神经网络在语音识别和图像分类等任务上的巨大成功。
-
2013年,AlexNet:第一个现代深度卷积网络模型,是深度学习技术在图像分类上取得真正突破的开端。
-
AlexNet不用预训练和逐层训练,首次使用了很多现代深度网络的技术。
-
随着大规模并行计算以及GPU设备的普及,计算机的计算能力得以大幅提高。此外,可供机器学习的数据规模也越来越大。在计算能力和数据规模的支持下,计算机已经可以训练大规模的人工神经网络。
三、为什么要研究深度学习
机器学习的特征问题
-
原始的机器学习算法中的特征往往需要人为制定,而手动设计的功能往往被过度指定,而且特征有可能不完整,需要很长时间来设计和检验才能找到能够达到最佳训练效果的特征。
-
被指定的特征容易在学习过程中很快被适应,导致过拟合的问题。
深度学习在某些任务上的优异表现
-
在视觉上的人工智能任务、NLP(自然语言处理)、音频等任务上,深度学习具有非常优异的表现。
-
通过大数据量和深度学习训练的时间来换取模型的泛用性,达到时间换取空间的目的。
深度学习的有效性
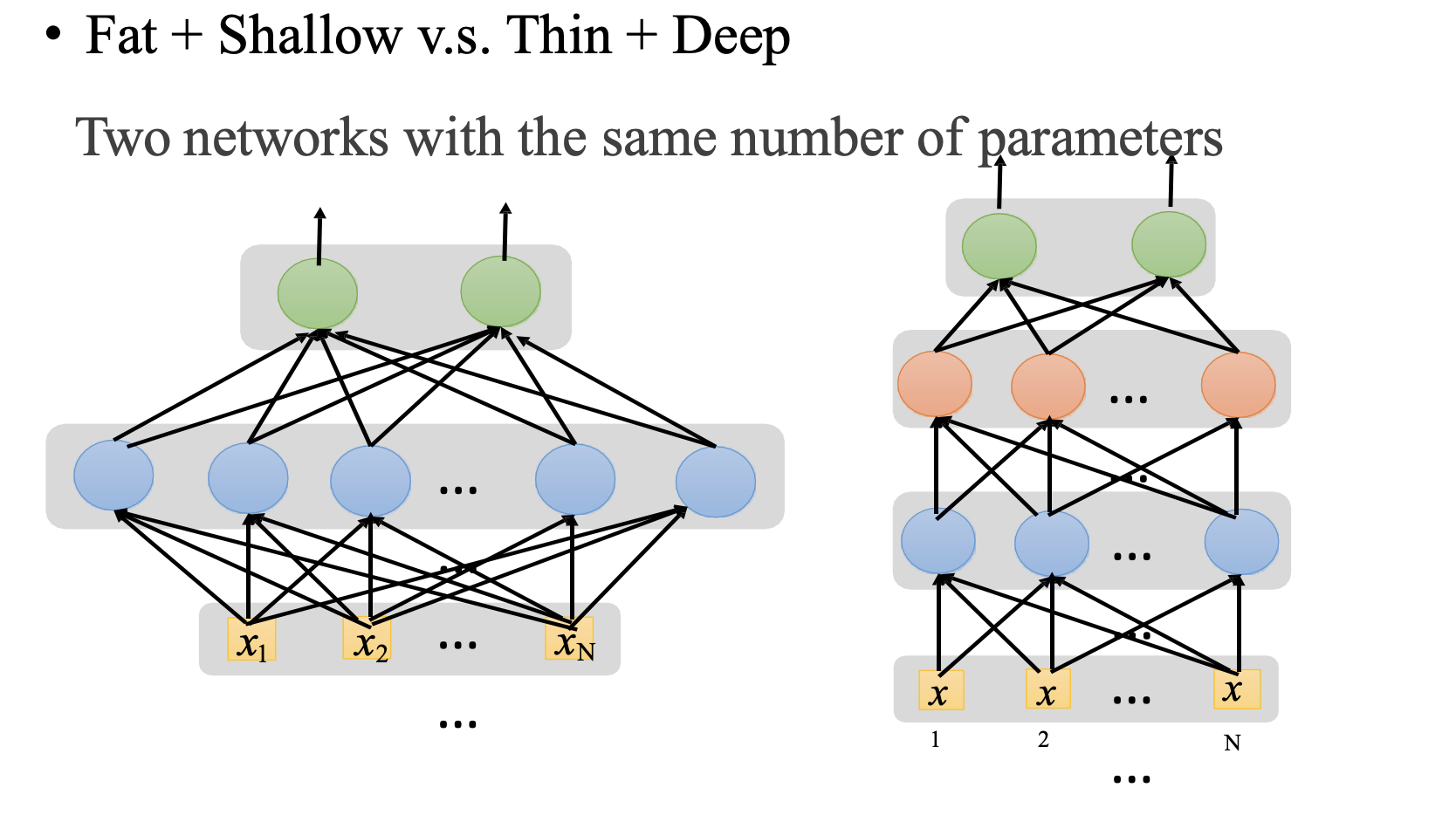
- 在同等参数个数的训练环境下,浅度学习(只有一个隐藏层)和深度学习直接的准确度的差距:

参考链接:
- 0
-
分享